





 Рейтинг: 4.6/5.0 (1682 проголосовавших)
Рейтинг: 4.6/5.0 (1682 проголосовавших)Категория: Программы
Недавно мой арсенал seo программ пополнился ещё одним замечательным софтом.
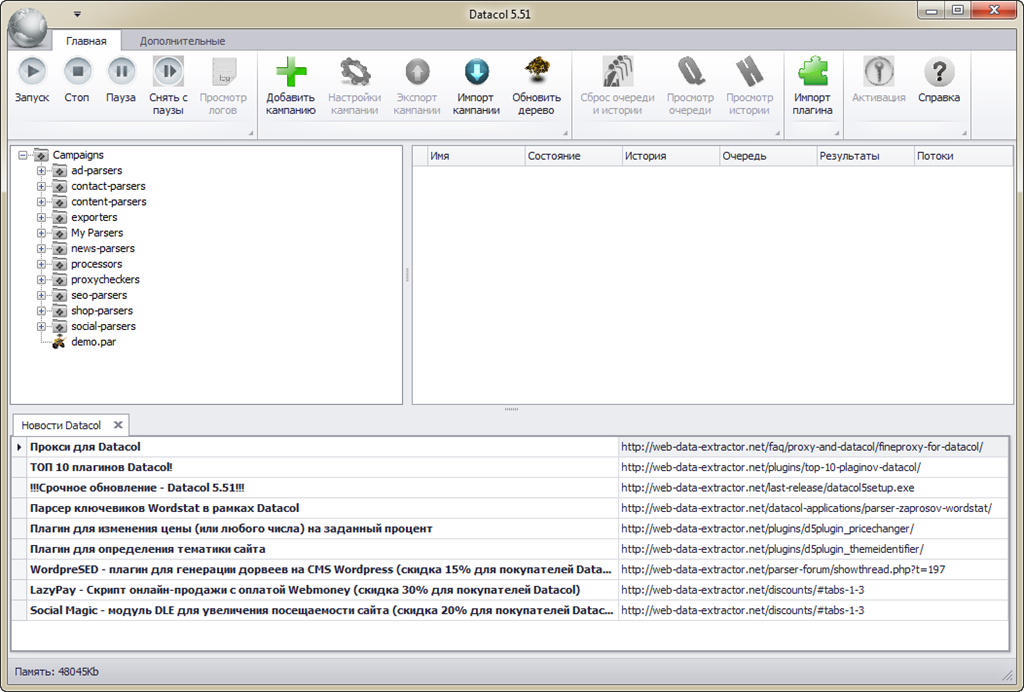
Datacol – это универсальное средство, с помощью которого можно собирать данные с любых сайтов в сети Интернет.
Сразу после того, как программа скачана и установлена Вы получаете доступ к множеству готовых парсеров, которые умеют:
А универсальным данный софт называют за то, что по помимо готовых парсеров контента Вы за считанные минуты можете сделать свой индивидуальный парсер, который будет собирать данные с нужного Вам вебресурса.
Для примера я решил сделать небольшой парсер, который будет собирать отзывы о товарах на сайте fotomag.com.ua
Что было сделано:
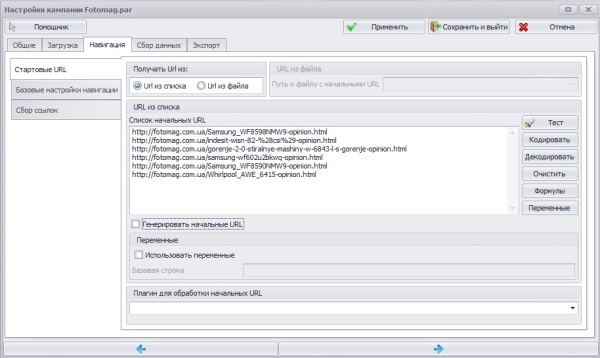
Создал новую компанию — Fotomag.par, заморачиваться с парсингом всего сайта пока не стал, а просто указал список url с которых нужно собрать отзывы (Вкладка Навигация ->Стартовые URL ).
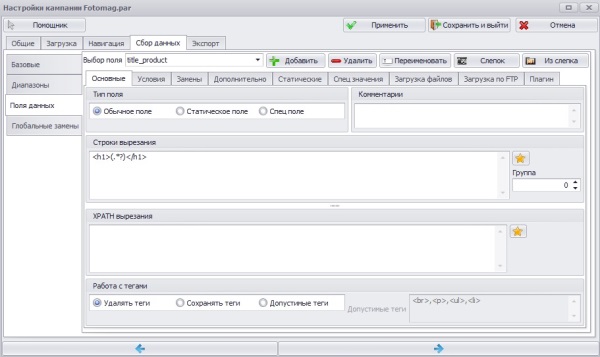
Во вкладке Сбор данных ->Поля данных создал 3и поля данных в которые будет записываться нужная информация (url страницы с отзывами о товаре, название товара и сами отзывы).
Первое поле. title_product;
Тип данных. обычное поле;
Строки вырезания :
С помощью данного регулярного выражения получаем данные стоящие между тегами h1, а именно — название товара.
В остальных вкладках ничего не менял.
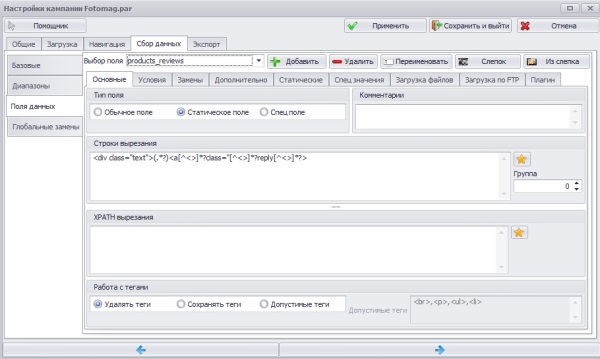
Второе поле. products_reviews;
Тип данных. статическое поле;
Строки вырезания :
С помощью данного регулярного выражения получаем данные стоящие между тегом div с классом text и тегом a с классом reply. а именно — отзыв о товаре.
Во вкладке Дополнительно установил галочку в Поле обязательное. чтоб в случае, если на странице не будет найдено отзывов, группа данных текущего диапазона не сохранялась.
Во вкладке Статические. по умолчанию оставил выбор всех значений, а в качестве строки объединения задал точку с запятой. Собственно особенность статического поля в том, что можно получить не только первое найденное значение (первый отзыв), а собрать все либо указать нужный диапазон данных.
Третье поле. url;
Тип данных. спец поле.
Во вкладке Спец значения. по умолчанию оставил выбранным URL.

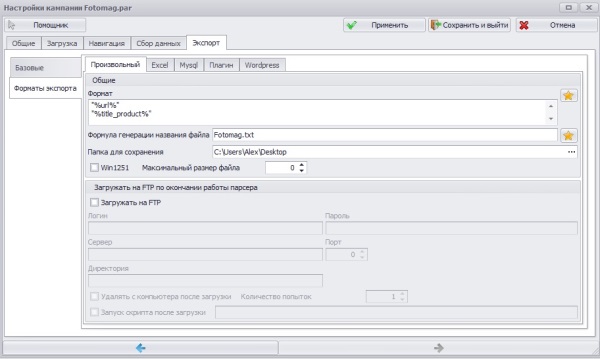
Во вкладке Экспорт ->Базовые выбрал произвольный формат экспорта и экспортировать в потоковом режиме.
Во вкладке Экспорт ->Форматы экспорта указал путь для сохранения собранных данных, записывать решил в текстовый файлик, а в качестве формата выбрал следующий:
"%url%" "%title_product%" Rewiews: "%products_reviews%"
После запуска, в области показа новостей и результатов можно увидеть группы данных собранные в процессе работы парсера.
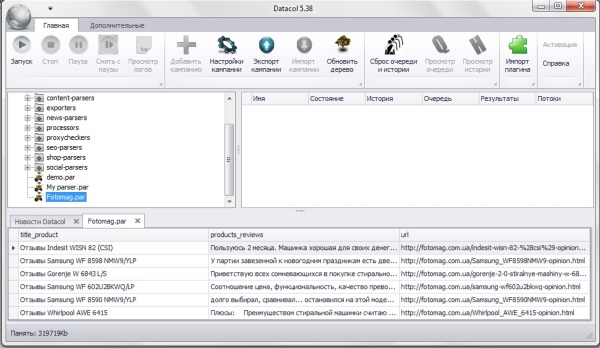
Работать с программой очень просто, главное на начальном этапе уделить несколько часов и ознакомиться с имеющейся справкой, в которой подробно расписан весь имеющийся функционал. Кроме того, на YouTube полно обучающих роликов по созданию парсеров на базе Datacol. Думаю со временем, когда сам больше поднатаскаюсь в создании парсеров тоже запишу какое-нибудь обучающее видео.
С помощью Datacol можно не только парсить любые данные, в программе есть функция экспорта данных в WordPress c помощью которой можно легко наполнять армию Ваших блогов. Базовый функционал Datacol также позволяет наполнять интернет магазины на Webasyst, Opencart и Virtuemart.
Отдельно можно приобрести плагины для экспорта данных в другие популярные движки: DLE. Joomla. Blogspot. Livejournal и др. С полным перечнем доступных платных и бесплатных плагинов можно ознакомиться на странице — Плагины Datacol .
Довольно важным моментом является и то, что разработчики Datacol занимаются поддержкой своего проекта и регулярно выпускают обновления, в которых устраняют найденные баги и добавляют новый функционал.
На текущий момент цена одной лицензии составляет 59$ (вместо 89$), на офф. сайте программы написано, что стоимость была снижена на период новогодних праздников, так что не исключено, что со временем снова подорожает. Если за время прочтения данного поста у Вас тоже появились мысли о том, как можно использовать данный софт в своей работе, ещё есть возможность сделать себе новогодний подарок и приобрести Datacol по сниженной цене.











Технические требования для работы программы:
Отличия между демонстрационной и рабочей версиями программы:
Вы можете опробовать софт, не покупая лицензионный ключ - демо-версия StandartHarvester будет выполнять все свои функции по парсингу сайтов и выявлению контактов, а также определению региональности и сферы деятельности организаций. Единственно ограничение в демо-версии - в результате парсинга, найденные электронные адреса и другие данные - не будут записываться в файл.
Стоимость ключа активации - 2900 рублей (лицензия на 1 год).
Запуск демо-версии StandartHarvester
Специалист службы поддержки ответит Вам на любой вопрос, связанный с нашей программой, заданный через систему тикетов в личном кабинете. По телефону - поддержку мы не оказываем, из-за того что пользователи часто не могут нормально сформулировать свой вопрос по телефону. Правильно поставленный письменный вопрос - уже на половину решенная проблема.
В случае необходимости - мы готовы оказать помощь через "удаленное управлением" Вашим компьютером.
Время необходимое на освоение StandartHarvesterСоздание и поддержка конкурентоспособного интернет-магазина не ограничивается только разработкой самого сайта. Основную ценность несет в себе информация, которую Вы хотите разместить в сети и ознакомить с ней потенциальных или реальных клиентов.

Найти нужные данные в сети и структурировать их поможет парсер сайтов E-Trade Content Creator – это программа, которая позволит автоматически собрать в одной базе информацию, размещенную на разных Интернет-ресурсах. Бесплатный парсер сайтов доступен в Demo-версии, но он имеет несколько ограничений в работе. Платные версии программы позволят Вам не беспокоиться о количестве товаров, описаний, которые можно собрать по каждой позиции, возможности многопользовательской работы и других нюансах.

Зачем нужен парсер сайтов
Ситуации, в которых приходится обновлять содержимое сайта, можно разделить на несколько категорий:





Чтобы оценить необходимость покупки программы E-Trade Content Creator, предлагаем Вам простые расчеты.

Представим ситуацию, при которой менеджеру нужно найти описание всего для одного товара:
Таким образом, на формирование карточки товара в собственной базе данных компании менеджер, в зависимости от квалификации и объемов искомой информации, тратит минимум 4-5 минут. За один рабочий день можно сформировать базу не более чем из 80-90 товаров при условии, что менеджер сразу попадет на нужный сайт, и информация на нем окажется ценной.
Это время вычислено при условии, что нужное описание найдено с первого раза, а это не всегда соответствует действительности. Чаще всего, для получения качественного списка характеристик требуется тщательный анализ десятков, а то и сотен сайтов. Время, которое уйдет на формирование карточки товара, может занять от получаса до целого рабочего дня. В условиях динамичного ведения бизнеса подобные сроки неприемлемы, поэтому имеет смысл использовать парсер интернет-магазина. Скачать программу E-Trade Content Creator и попробовать ее в тестовом режиме можно на нашем сайте.
Дополнительная информация:Парсеры — это программы или скрипты, осуществляющие сбор различного контента с других сайтов. В зависимости от требований могут быть настроены на полное или частичное копирование контента выбранного сайта. Разделяются на узкоспецилизированные (копируют текст или изображения) и универсальные (копируют текст и картинки вместе). В основном используются для парсинга контента сайтов и результатов выдачи поисковых систем. Парсеры сайтов помогают вебмастеру собирать контент, анализировать его и наполнять им свои проекты.
Популярные парсеры сайтов Парсер «Ночной дозор»
«НОЧНОЙ ДОЗОР» — программа для быстрого получения целевой информации с любых сайтов и последующей ее публикацией на других ресурсах. Представляет собой универсальный парсер контента со встроенным синонимайзером, что позволяет получать награбленный контент уже уникальным. В настройках парсера можно задать любые параметры для сбора информации.
Парсинг происходит посредством составления макросов, после чего программа в автоматическом режиме выполняет запрограмированные действия без вашего участия и присмотра. Это позволяет использовать программу в любое удобное время суток на полном автомате. Поддерживает все популярные CMS: WordPress, Joomla, DLE, Drupal, Ucoz а также самописные. Работает в фоновом режиме или по расписанию.
На данное время программа вне конкуренции от других, одно из главных отличий этого парсера, не требует от пользователя знаний программирования. Русский интерфейс, видео уроки по работе, делают программу доступной любому пользователю. СКАЧАТЬ

Uni Parse — бесплатный граббер текста под любые нужды и цели. Шустрый, многопоточный граббер собирает также ссылки со страниц сайтов. Работать легко и удобно. В поле «сайт» вставляете нужный URL со слешем на конце «/». Выставляете нужное количество потоков, редактируете «Black list» потом жмем на старт. На выходе в папке «up»получите текстовый файл с адресами. Чтобы начать парсинг текста, ставим галочку на «селективный парсинг», потом жмем «SelectiveParse». Заполняем поля с настройками, запускаем парсинг. Подробнее по настройке, а также скачать можно здесь .
Sjs парсер
Sjs парсер — популярный в среде вебмастеров, универсальный парсер контента. Умеет спарсить как определенную часть контента сайта или полностью весь сайт. Способен разделять информацию и обрабатывать ее в соответствии с поставленной задачей.
Граббер очень легко настроить под свои потребности или нужды. Например для наполнения интернет-магазина или каталогов. К сожалению автор свой проект больше не поддерживает. Но скачать парсер Sjs в сети можно без проблем.
Парсеры сайтов помогают вебмастеру без особого труда собрать нужную информацию за минимум времени
Советую почитать:
Иногда существует необходимость собрать какой-нибудь контент с других ресурсов интернета, но вручную это делать крайне сложно, особенно если речь идет о тысячах страниц. В таком случае приходится либо самому писать парсер под конкретный сайт, либо заказывать его у программиста, если сами с программированием не дружите. Однако сейчас существуют мощные программы, в том числе и бесплатные, способные выполнить большую часть требующихся задач по автоматизации выдергивания контента.
Самым многофункциональным и популярным является парсер Content Downloader. Возможности его перечислить не получится в одной статье – настолько их много. Программа умеет буквально все, а результат можно настраивать как угодно. К тому же она постоянно обновляется, добавляются все новые функции и макросы.
Коротко о том, что умеет Content Downloader:
1. Можно парсить контент с любых интернет магазинов, выбирая нужную информацию, просто кликая по ней мышкой. В программу встроен специальный браузер для этого. Сохранять результат можно в .txt файл. html или CSV.
2. Имеется возможность парсинга картинок с Google, включая настройки размера, и, естественно, поиска по ключевым словам.
3. Кроме текста программа умеет сохранять картинки, находящиеся на странице, файлы .torrent или приложения Flash.
4. Парсер может сканировать сайт на ссылки по указанному фильтру, чтобы затем обрабатывать страницы только по найденным ссылкам.
5. Есть поддержка авторизации пользователей и работы через прокси.
На этом возможности программы не исчерпываются, она практически может все, подходит под любые ресурсы, так как является универсальной и обладает гибкими настройками.
Естественно, она не может быть бесплатной, но существует 3 вида лицензии: 1000, 1500 и 2000 рублей, в зависимости от того, что вам нужно.
Следующим идет неплохой парсер контента Ночной Дозор (его еще называют иногда Ночной Бдун).
Все возможности программы доступны только в платной версии, но и бесплатную можно использовать в некоторых случаях, вот ее возможности:
1. Имеется возможность добавить необходимые сайты и категории на них, из которых будет выдираться контент. Для экономии трафика и времени, предусмотрена возможность загрузки облегченных версий страниц ”для печати”, если таковые имеются.
2. Полная настройка сбора контента, который вам нужен. Можно, например, картинки загрузить в последнюю очередь, уже когда страницы были сохранены.
3. Вывод и сохранение результата тоже полностью настраиваемо. Можно даже в результате получить уже готовые страницы с каталогами и материалами.
Наконец, существует полностью бесплатный парсер, под названием UniParse. Большим количеством возможностей похвастаться не может, но для бесплатного приложения он очень даже ничего. Здесь тоже имеется настройка фильтров ссылок, с которых будет закачиваться контент. Результаты можно сохранять в один текстовый файл или много, предусмотрена возможность удаления файлов маленького размера.
Программа отлично подойдет вам, если необходимо выдергивать новости или статьи с разнообразных сайтов. Для более сложных задач лучше использовать парсеры, о которых говорилось выше.